Abstract
Task specification for robotic manipulation in open-world environments is inherently challenging. Importantly, this process requires flexible and adaptive objectives that align with human intentions and can evolve through iterative feedback. We introduce Iterative Keypoint Reward (IKER), a framework that leverages VLMs to generate and refine visually grounded reward functions serving as dynamic task specifications for multi-step manipulation tasks. Given RGB-D observations and free-form language instructions, IKER samples keypoints from the scene and utilizes VLMs to generate Python-based reward functions conditioned on these keypoints. These functions operate on the spatial relationships between keypoints, enabling precise SE(3) control and leveraging VLMs as proxies to encode human priors about robotic behaviors. We reconstruct real-world scenes in simulation and use the generated rewards to train reinforcement learning policies, which are then deployed into the real world—forming a real-to-sim-to-real loop. Our approach demonstrates notable capabilities across diverse scenarios, including both prehensile and non-prehensile tasks, showcasing multi-step task execution, spontaneous error recovery, and on-the-fly strategy adjustments. The results highlight IKER's effectiveness in enabling robots to perform multi-step tasks in dynamic environments through iterative reward shaping and minimal interaction.
Video
Iterative Keypoint Reward (IKER)
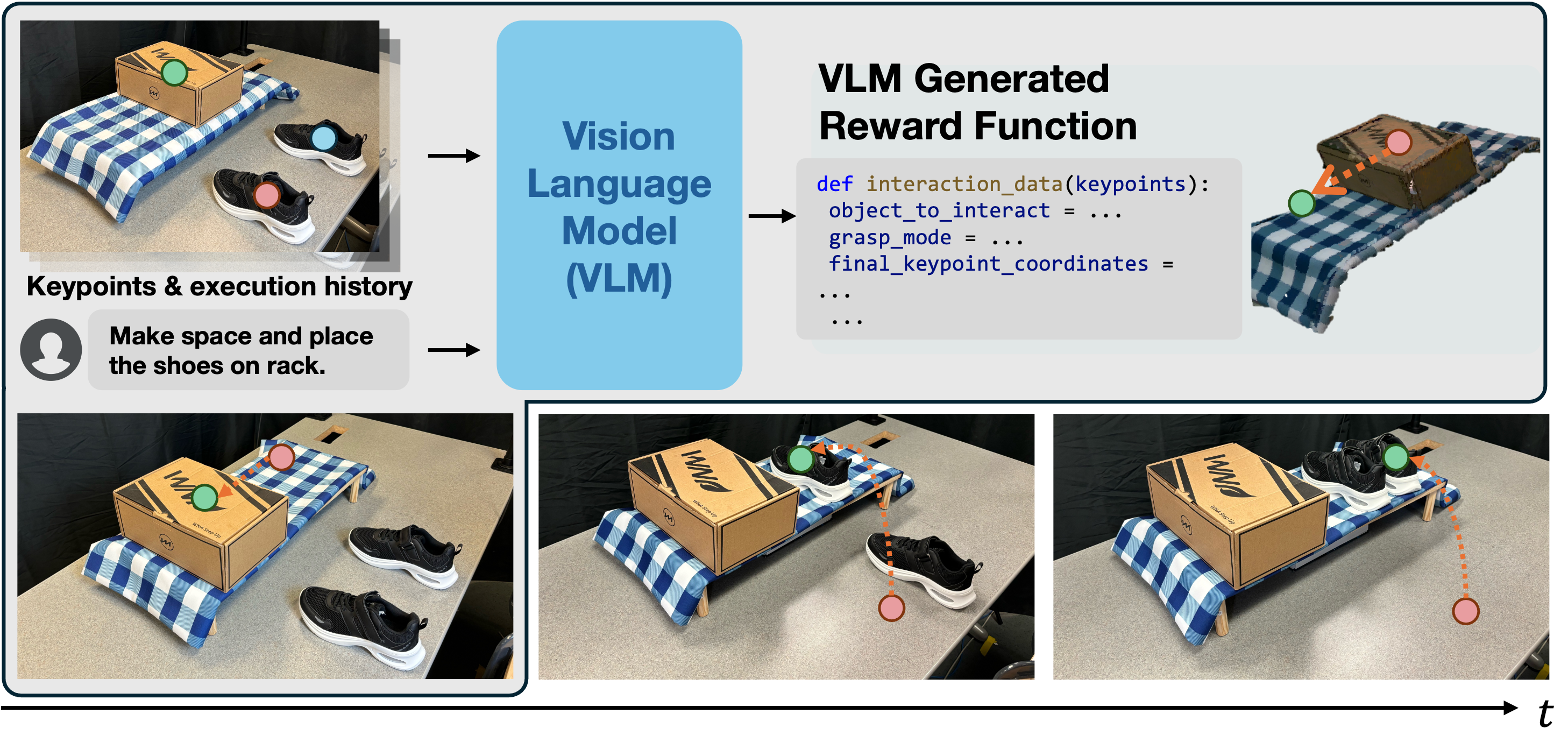
Given RGB-D observations, we first obtain keypoints in the scene. These keypoints, overlaid on the scene along with human commands and execution history, are passed through GPT-4o, which maps the keypoints into a reward function, allowing the robot to follow task objectives. We call these reward functions Iterative Keypoint Reward (IKER). IKER is generated iteratively and is dynamic and adaptable. By capturing spatial relationships between keypoints, IKER enables precise SE(3) control of objects.
Method Overview

Our framework follows a real-to-sim-to-real approach to robotic manipulation. First, the real-world scene is reconstructed in simulation using 3D meshes of objects and point cloud of the environment. GPT-4o generates IKER using real-world observations which is then used to train reinforcement learning policy in simulation This policy is subsequently deployed in the real-world. Domain randomization is employed during training to bridge the real-to-sim and sim-to-real gap, making policies robust in real-world scenarios. The framework supports both prehensile and non-prehensile tasks and includes features like multi-step task chaining and error recovery, which allow robots to adapt dynamically during task execution.
Skills & Chaining
Robustness
Since our plans are closed-loop, our framework is robust to disturbances. On the left, a human intervenes with robot execution. On the right, the robot makes a mistake by placing the left shoe little far. In both the cases, robot is able to correct the behavior.
Replan to Regrasp
Our framework can predict new plans when previous plans are unfeasible. In this case, the robot fails grasping the book. It proposes a new plan to first push the book to make it graspable, and then stows it.
Results
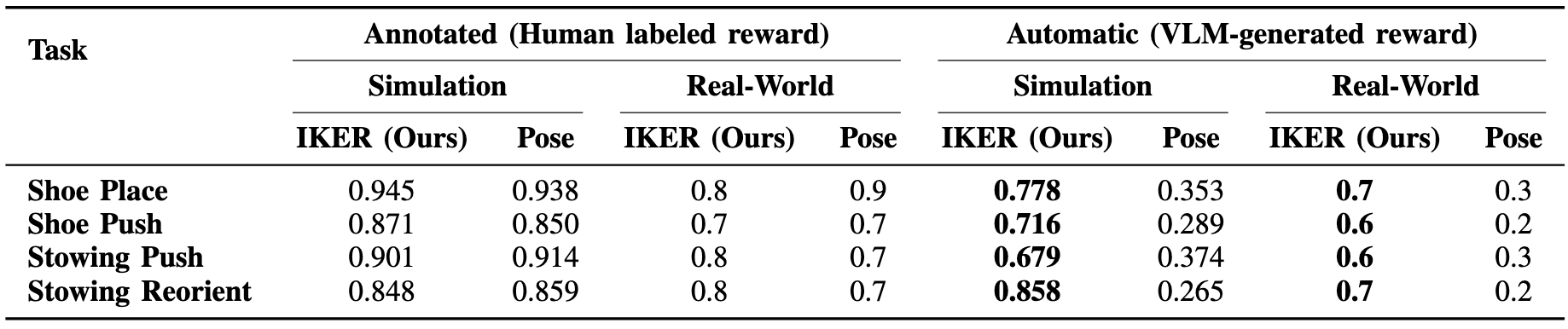
We present results demonstrating the effectiveness of using keypoints over object poses to query VLMs in both simulation and real-world. The key findings are as follows:
- Both keypoints and object poses effectively specify SE(3) task objectives, providing robust guidance for manipulation tasks.
- VLMs exhibit superior reasoning capabilities when processing keypoints compared to object poses, leading to more accurate task execution.
- Automatic reward generation using VLMs performs worse than human annotated variants, highlighting limitations of current VLM predictions.
- The observed sim-to-real gap is minimal, highlighting the success of domain randomization in bridging real-to-sim and sim-to-real gaps.